
Los Modelos QAT Gemma 3 de Google Democratizan la IA Avanzada para Hardware de Consumo
Google ha lanzado versiones cuantificadas de su potente modelo de lenguaje Gemma 3 27B QAT, permitiendo que la IA de última generación se ejecute en hardware de consumo. Las nuevas variantes de Entrenamiento Consciente de la Cuantización (QAT, por sus siglas en inglés) reducen drásticamente los requisitos de memoria, manteniendo un rendimiento comparable a sus contrapartes de precisión total, lo que marca un punto de inflexión en la incorporación de capacidades de IA avanzadas a los dispositivos personales.

Llevando la Potencia de una Supercomputadora a las GPU de Consumo
En un pequeño apartamento en Brooklyn, la desarrolladora de software Maya Chen ejecuta complejas tareas de generación de imágenes con IA y análisis de texto que normalmente requerirían costosos servicios en la nube o hardware especializado. ¿Su secreto? Una tarjeta gráfica NVIDIA RTX 3090 de hace dos años que ejecuta el modelo Gemma 3 27B QAT, recientemente lanzado por Google.
"Es revolucionario", explica Chen mientras demuestra el sistema. "Estoy ejecutando lo que equivale a una IA de nivel de supercomputadora en hardware que ya poseía. Antes de este lanzamiento, simplemente no era posible".
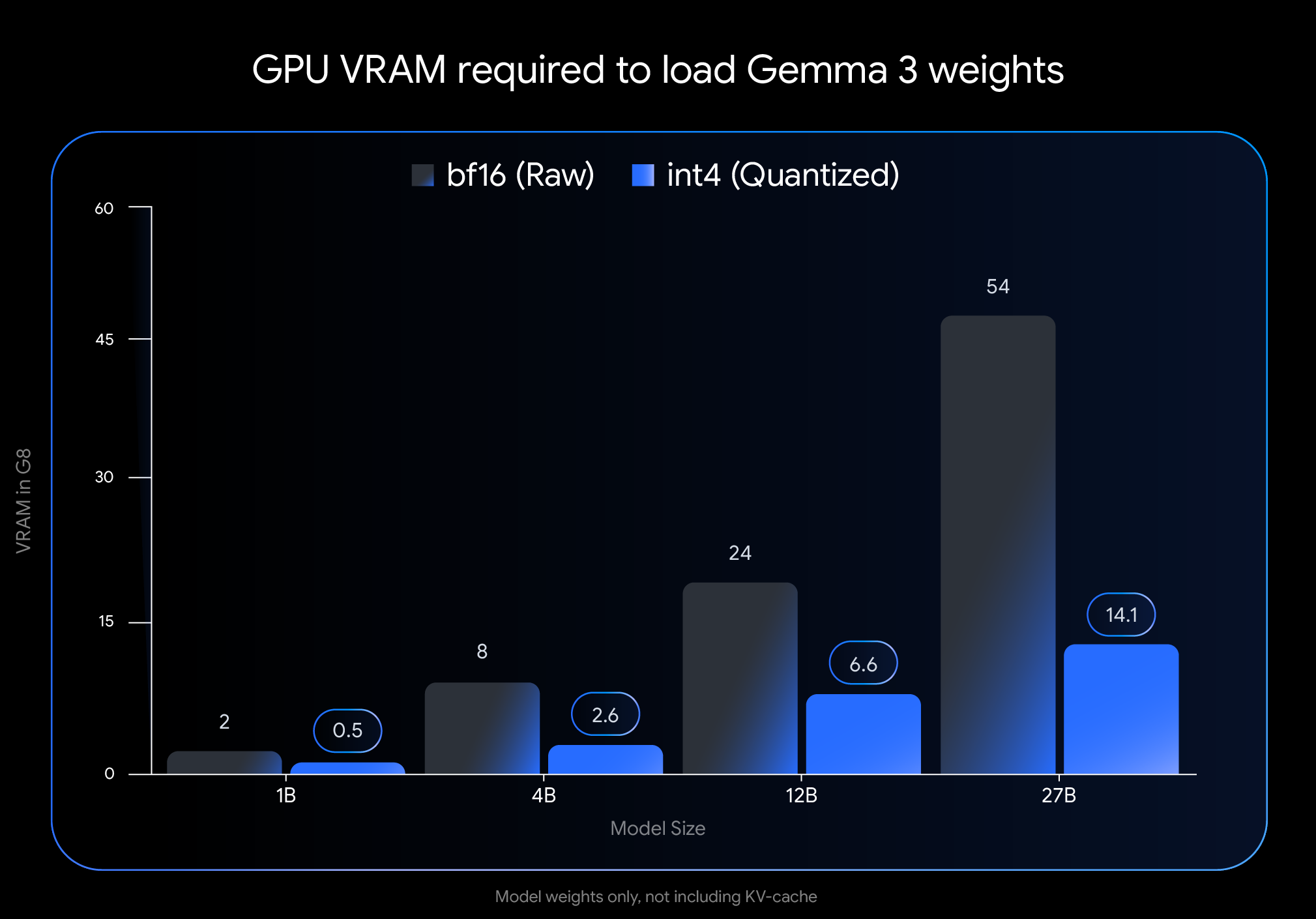
La experiencia de Chen refleja la promesa del anuncio de Google del 18 de abril: democratizar el acceso a la IA de vanguardia haciéndola funcionar de manera eficiente en hardware de consumo ampliamente disponible. El lanzamiento de Gemma 3 el mes pasado lo estableció como un modelo abierto líder, pero sus altos requisitos de memoria limitaron la implementación a hardware costoso y especializado. Las nuevas variantes QAT cambian esta dinámica por completo.
Avance Técnico en la Compresión de Modelos
Los modelos cuantificados representan un avance técnico en la compresión de modelos de IA. Los enfoques tradicionales para reducir el tamaño del modelo a menudo resultaban en una degradación significativa del rendimiento, pero la implementación de Google del Entrenamiento Consciente de la Cuantización introduce un enfoque novedoso.
A diferencia de los métodos convencionales de cuantificación posterior al entrenamiento, QAT incorpora el proceso de compresión durante la fase de entrenamiento en sí. Al simular operaciones de baja precisión durante el entrenamiento, los modelos se adaptan para funcionar de manera óptima incluso cuando finalmente se implementan con una precisión numérica reducida.
"Lo que hace que este enfoque sea particularmente efectivo es la metodología de entrenamiento", señala un investigador de aprendizaje automático que ha analizado los modelos. "Al aplicar QAT en aproximadamente 5000 pasos y usar probabilidades de puntos de control no cuantificados como objetivos, han reducido la caída de perplejidad en un 54% en comparación con las técnicas de cuantificación estándar".
El impacto en los requisitos de memoria es drástico. La huella de VRAM del modelo Gemma 3 27B se reduce de 54 GB a solo 14.1 GB, una reducción de casi el 74%. Del mismo modo, la variante de 12B cae de 24 GB a 6.6 GB, la de 4B de 8 GB a 2.6 GB y la de 1B de 2 GB a solo 0.5 GB.
Estas reducciones hacen que los modelos previamente inaccesibles sean viables en hardware de consumo. El modelo insignia de 27B ahora se ejecuta cómodamente en GPU de escritorio como la NVIDIA RTX 3090, mientras que la variante de 12B puede funcionar de manera eficiente en GPU de portátiles como la NVIDIA RTX 4060.
El Rendimiento en el Mundo Real Valida el Enfoque
Lo que separa la implementación de Google de los intentos anteriores de cuantificación de modelos es el impacto mínimo en el rendimiento. Los puntos de referencia independientes sugieren que los modelos QAT mantienen una precisión dentro del 1% de sus contrapartes de precisión total.
En las clasificaciones Elo de Chatbot Arena, una medida ampliamente respetada del rendimiento del modelo de IA basada en las preferencias humanas, los modelos Gemma 3 obtienen puntajes impresionantemente altos. La variante de 27B alcanza una puntuación Elo de 1338, lo que la sitúa entre los mejores modelos abiertos a pesar de requerir significativamente menos potencia informática que sus competidores.
Los comentarios de la comunidad corroboran estas métricas oficiales. Los usuarios en los foros de desarrolladores informan que los modelos QAT "se sienten más inteligentes" que otras variantes cuantificadas. En comparaciones directas utilizando la desafiante métrica GPQA diamond, el Gemma 3 27B QAT superó a otros modelos cuantificados mientras usaba menos memoria.
"Hemos visto tiempos de respuesta casi instantáneos en aplicaciones en tiempo real", dice un desarrollador que integró el modelo en una aplicación móvil. "Esto hace que Gemma 3 sea práctico para implementaciones en el borde donde la latencia y las limitaciones de recursos son factores críticos".
Las Capacidades Multimodales Amplían los Casos de Uso
Más allá del rendimiento bruto, Gemma 3 incorpora innovaciones arquitectónicas que amplían sus capacidades más allá del procesamiento de texto. La integración de un codificador de visión permite a los modelos procesar imágenes junto con texto, aunque algunos expertos señalan limitaciones en la profundidad de la comprensión visual en comparación con sistemas especializados más grandes.
Otro avance significativo es el soporte para ventanas de contexto extendidas: hasta 128,000 tokens para la mayoría de las variantes y 32,000 para el modelo 1B. Esto permite que la IA procese documentos y conversaciones mucho más largos que la mayoría de los modelos accesibles para el consumidor.
"La implementación de un mecanismo de atención local/global intercalado reduce drásticamente la huella de memoria requerida para la inferencia de contexto largo", explica un ingeniero de aprendizaje automático familiarizado con la arquitectura. "Esto hace que sea factible procesar documentos extensos en GPU de consumo sin sacrificar la comprensión".
El Soporte del Ecosistema Facilita la Adopción
Google ha priorizado la facilidad de integración, lanzando los modelos en formatos compatibles con herramientas populares para desarrolladores. Los modelos QAT no cuantificados int4 y Q4_0 oficiales están disponibles en Hugging Face y Kaggle, con soporte nativo de herramientas como Ollama, LM Studio, MLX para Apple Silicon, Gemma.cpp y llama.cpp.
Este soporte del ecosistema ha acelerado la adopción entre desarrolladores e investigadores independientes. Los foros de discusión están llenos de informes de implementaciones exitosas en diversas configuraciones de hardware y casos de uso.
"El amplio soporte de herramientas y el proceso de configuración fácil han sido cruciales", dice un desarrollador que integró el modelo en una aplicación educativa. "Pudimos implementar localmente en cuestión de horas, eliminando los costos de la nube y manteniendo la calidad de la respuesta".
Limitaciones y Direcciones Futuras
A pesar de los avances, los expertos identifican varias áreas donde los modelos Gemma 3 aún enfrentan limitaciones. Si bien pueden procesar contextos largos, algunos usuarios notan que la capacidad de razonar profundamente a través de entradas muy extensas sigue siendo un desafío, particularmente para tareas analíticas complejas.
El componente de visión, aunque eficiente, no es tan sofisticado como en algunos modelos multimodales más grandes, entrenados conjuntamente. Esto puede afectar el rendimiento en tareas que requieren una comprensión visual matizada.
Además, algunos investigadores de aprendizaje automático señalan que gran parte del rendimiento de Gemma 3 proviene de una sofisticada destilación de conocimiento de modelos maestros más potentes, probablemente de la familia Gemini patentada de Google. Esta dependencia, junto con cierta opacidad en la metodología posterior al entrenamiento, limita la reproducibilidad total por parte de la comunidad de investigación de IA más amplia.
Democratizando el Desarrollo de la IA
El lanzamiento representa un paso significativo para hacer que las capacidades avanzadas de IA sean accesibles a una gama más amplia de desarrolladores, investigadores y entusiastas. Al permitir la implementación local en hardware común, los modelos Gemma 3 QAT reducen las barreras de entrada en términos de costo y requisitos técnicos.
"Se trata de algo más que de capacidades técnicas", reflexiona Chen, la desarrolladora de Brooklyn. "Se trata de quién puede innovar con estas tecnologías. Cuando una IA poderosa se ejecuta localmente en hardware de consumo, abre puertas a individuos y pequeños equipos que no podían permitirse una infraestructura especializada".
A medida que la IA influye cada vez más en varios aspectos del desarrollo tecnológico, la capacidad de ejecutar modelos sofisticados localmente puede resultar transformadora para la innovación más allá de las principales empresas de tecnología. El enfoque de Google con Gemma 3 QAT sugiere un futuro donde la IA de última generación se convierta en una herramienta democratizada en lugar de un recurso centralizado.
Si esta visión se materializa por completo depende de cómo evolucione la tecnología y de cómo la comunidad de desarrolladores en general adopte estas capacidades. Por ahora, sin embargo, la brecha entre la investigación de IA de vanguardia y la implementación práctica se ha reducido significativamente, un desarrollo con implicaciones potencialmente de gran alcance para el futuro de la accesibilidad de la IA.