
ByteDance presenta Seed 1.5-VL: Un modelo de IA de visión-lenguaje revolucionario que compite con Gemini Pro 2.5
En un gran avance para la inteligencia artificial multimodal, el equipo Seed de ByteDance ha lanzado su último modelo grande de visión-lenguaje, Seed 1.5-VL, marcando un hito importante en la carrera global de la IA. Diseñado con solo 20 mil millones de parámetros activados, Seed 1.5-VL ofrece un rendimiento comparable al de Gemini 2.5 Pro de Google, estableciendo puntos de referencia de vanguardia (SOTA) en un amplio espectro de tareas visuales e interactivas del mundo real, todo con costos de inferencia sustancialmente reducidos.
🚀 ¿Qué sucedió?
El 15 de mayo de 2025, ByteDance lanzó oficialmente Seed 1.5-VL, la última evolución de su serie Seed de modelos de IA multimodales. Preentrenado con más de 3 billones de tokens de datos multimodales de alta calidad —incluyendo texto, imágenes y videos— Seed 1.5-VL combina razonamiento visual avanzado, comprensión de imágenes, interacción con GUI y análisis de video en una arquitectura única y optimizada.
A diferencia de los sistemas de IA voluminosos, Seed 1.5-VL se basa en una arquitectura de Mezcla de Expertos (MoE), que activa solo un subconjunto de sus 20 mil millones de parámetros totales para cada tarea. Esto mejora drásticamente la eficiencia computacional, haciéndolo ideal para aplicaciones de IA interactivas y en tiempo real en entornos de escritorio, móviles y embebidos.
A pesar de su tamaño relativamente compacto, Seed 1.5-VL obtuvo resultados SOTA en 38 de los 60 puntos de referencia de evaluación pública, incluyendo:
- 14 de 19 puntos de referencia de comprensión de video
- 3 de 7 tareas de agente GUI
En las pruebas, sobresalió en razonamiento complejo, reconocimiento óptico de caracteres (OCR), interpretación de imágenes, detección de vocabulario abierto y análisis de video de seguridad.
Seed 1.5-VL ya está disponible públicamente para pruebas a través de la API de Volcano Engine y la comunidad de código abierto en Hugging Face y GitHub.
📌 Puntos clave
- Dominio multimodal: Maneja tareas de imágenes, video, texto y GUI con comprensión a nivel humano.
- Eficiencia primero: Solo 20 mil millones de parámetros activos, ofreciendo resultados comparables a Google Gemini 2.5 Pro con costos más bajos.
- Logros SOTA: Lidera en 38 de 60 puntos de referencia públicos, especialmente en tareas de video y GUI.
- Aplicaciones prácticas: Ya probado en OCR, análisis de vigilancia, reconocimiento de celebridades e interpretación de imágenes metafóricas.
- Acceso abierto: API activa en Volcano Engine, documento técnico en arXiv y código en GitHub.
🔍 Análisis profundo
Arquitectura e innovaciones
Seed 1.5-VL se basa en tres módulos principales:
- Codificador visual SeedViT: Un codificador de 532 millones de parámetros que extrae características ricas de imágenes y fotogramas de video.
- Adaptador MLP: Sirve de puente entre el codificador visual y el modelo de lenguaje al traducir las características de imágenes/video a tokens multimodales.
- Modelo de lenguaje grande (LLM): Un LLM basado en MoE de 20 mil millones de parámetros optimizado para la eficiencia de inferencia.
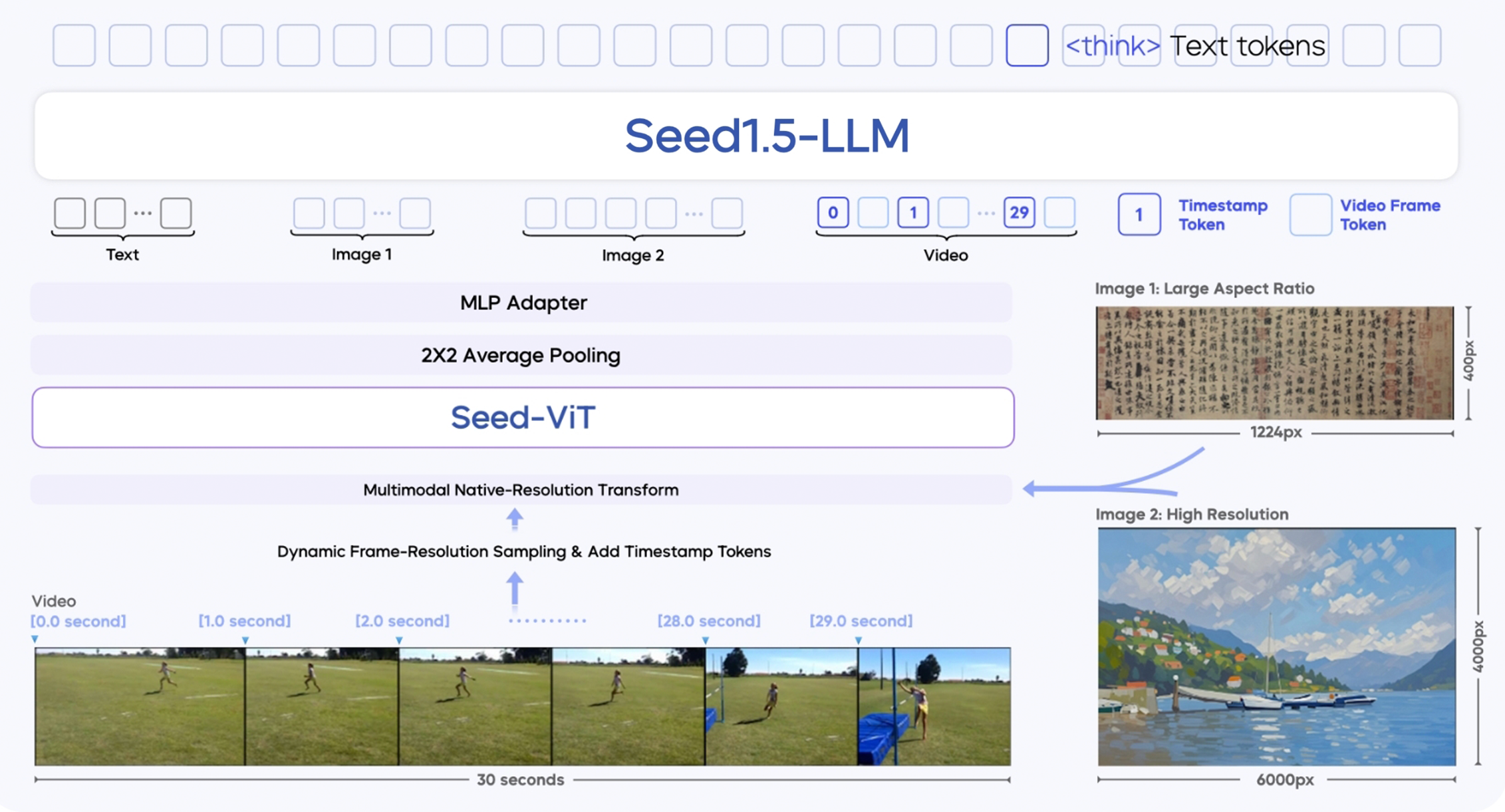
Introduce varias innovaciones técnicas:
- Soporte de entrada multi-resolución: Mantiene la calidad y precisión de la imagen.
- Muestreo dinámico de fotogramas por resolución: Mejora la comprensión de video seleccionando fotogramas según la complejidad del movimiento.
- Mejora temporal mediante tokens de marca de tiempo: Rastrea mejor las secuencias de objetos y la causalidad en los videos.
- Entrenamiento con más de 3 billones de tokens multimodales: Mejora la generalización en diferentes dominios.
- Refinamientos post-entrenamiento: Incluye muestreo por rechazo y aprendizaje por refuerzo en línea para ajustar la calidad de la respuesta.
Fortalezas
Seed 1.5-VL destaca en:
- Preguntas y respuestas visuales (VQA) e interpretación de gráficos
- Tareas de automatización de GUI, incluyendo juegos y control de aplicaciones
- Razonamiento interactivo en entornos visuales abiertos
- Aplicaciones del mundo real, como identificación de celebridades, vigilancia y comprensión de metáforas
Es elogiado por su robustez en el mundo real, algo que muchos modelos académicos carecen. Varios revisores incluso lo calificaron como una "potencia no estándar" capaz de competir con o4 de OpenAI y Gemini de Google.

Limitaciones
A pesar de sus fortalezas, Seed 1.5-VL no es perfecto:
- Desafíos visuales de grano fino: Lucha con el conteo de objetos bajo oclusión, la similitud de colores o disposiciones irregulares.
- Razonamiento espacial complejo: Tareas como navegar por laberintos o resolver rompecabezas deslizantes pueden arrojar resultados incompletos.
- Inferencia temporal: Surgen dificultades al rastrear secuencias de acciones a través de los fotogramas.
Estas son áreas que ByteDance reconoce y probablemente está abordando en futuras versiones.
Contexto competitivo
Seed 1.5-VL se lanza en medio de una carrera armamentística de la IA:
- Gemini 2.5 Pro de Google (6 de mayo de 2025) domina las clasificaciones multimodales (LMArena).
- o3 y o4-mini de OpenAI (17 de abril de 2025) impulsan el uso de herramientas multimodales y el aprendizaje por refuerzo.
- Competidores nacionales como Tencent y Doubao han mejorado sus capacidades de imagen y voz.
Los analistas de inversión son optimistas: los modelos de agente y las capacidades multimodales se consideran motores clave de las aplicaciones de IA de próxima generación, particularmente en software empresarial, ERP, OA, asistentes de codificación y herramientas de oficina.
💡 ¿Sabías qué?
- Seed 1.5-VL puede detectar comportamientos sospechosos en videos de vigilancia, un caso de uso avanzado en el mundo real que pocos modelos abordan eficazmente.
- Es uno de los pocos modelos capaces de leer imágenes metafóricas y explicar las relaciones abstractas dentro de ellas.
- Solo 3 modelos a nivel global (Gemini Pro 2.5, OpenAI o4, Seed 1.5-VL) son actualmente capaces de control GUI interactivo, en tiempo real y cross-modal.
- ByteDance logró competir con el rendimiento de Gemini Pro utilizando muchos menos parámetros, mostrando habilidades de compresión y optimización de modelos de élite.
- Seed 1.5-VL utiliza una transformación nativa que conserva la resolución que evita la degradación de calidad común en los codificadores visuales tradicionales.
Reflexiones finales
Seed 1.5-VL marca un hito importante para ByteDance en el establecimiento como un líder global en investigación de IA, particularmente en modelos fundacionales multimodales. Con una eficiencia de rendimiento incomparable, una capacidad robusta en el mundo real y logros SOTA en puntos de referencia clave, no solo se mantiene al día con Google y OpenAI, sino que compite directamente.
A medida que la adopción de la IA se profundiza en todas las industrias, modelos como Seed 1.5-VL estarán a la vanguardia, dando forma a agentes inteligentes, potenciando la automatización y redefiniendo lo que las máquinas pueden percibir, comprender y hacer.
Editor CTOL Ken: Recomiendo encarecidamente echar un vistazo a los ejemplos en la página oficial de Seed 1.5-VL de ByteDance; son realmente impresionantes.