
Cómo Elegir GPUs para Aprendizaje Profundo y Modelos de Lenguaje Grandes
Al seleccionar GPUs para cargas de trabajo de aprendizaje profundo, especialmente para entrenar y ejecutar modelos de lenguaje grandes (LLMs), se deben considerar varios factores. Aquí tienes una guía completa para tomar la decisión correcta.
Tabla: Últimos LLMs de Código Abierto Líderes y sus Requisitos de GPU para Despliegue Local
| Modelo | Parámetros | Requisito de VRAM | GPU Recomendada |
|---|---|---|---|
| DeepSeek R1 | 671B | ~1,342GB | NVIDIA A100 80GB ×16 |
| DeepSeek-R1-Distill-Qwen-1.5B | 1.5B | ~0.7GB | NVIDIA RTX 3060 12GB+ |
| DeepSeek-R1-Distill-Qwen-7B | 7B | ~3.3GB | NVIDIA RTX 3070 8GB+ |
| DeepSeek-R1-Distill-Llama-8B | 8B | ~3.7GB | NVIDIA RTX 3070 8GB+ |
| DeepSeek-R1-Distill-Qwen-14B | 14B | ~6.5GB | NVIDIA RTX 3080 10GB+ |
| DeepSeek-R1-Distill-Qwen-32B | 32B | ~14.9GB | NVIDIA RTX 4090 24GB |
| DeepSeek-R1-Distill-Llama-70B | 70B | ~32.7GB | NVIDIA RTX 4090 24GB ×2 |
| Llama 3 70B | 70B | ~140GB (estimado) | NVIDIA 3000 series, 32GB RAM mínimo |
| Llama 3.3 (modelos más pequeños) | Varía | Al menos 12GB VRAM | NVIDIA RTX 3000 series |
| Llama 3.3 (modelos más grandes) | Varía | Al menos 24GB VRAM | NVIDIA RTX 3000 series |
| GPT-NeoX | 20B | 48GB+ VRAM total | Dos NVIDIA RTX 3090 (24GB cada una) |
| BLOOM | 176B | 40GB+ VRAM para entrenamiento | NVIDIA A100 o H100 |
Consideraciones Clave al Elegir GPUs
1. Requisitos de Memoria
- Capacidad de VRAM: Quizás el factor más crítico para los LLMs. Los modelos más grandes requieren más memoria para almacenar parámetros, gradientes, estados del optimizador y muestras de entrenamiento en caché.
** Tabla: Importancia de la VRAM en los Modelos de Lenguaje Grandes (LLMs).**
| Aspecto | Función de la VRAM | Por Qué Es Crucial | Impacto si Es Insuficiente |
|---|---|---|---|
| Almacenamiento del Modelo | Guarda los pesos y capas del modelo | Necesaria para un procesamiento eficiente | Se descarga a memoria más lenta; gran caída de rendimiento |
| Computación Intermedia | Almacena activaciones y datos intermedios | Permite pasos de propagación hacia adelante/atrás en tiempo real | Limita el paralelismo y aumenta la latencia |
| Procesamiento por Lotes | Soporta tamaños de lote más grandes | Mejora el rendimiento y la velocidad | Lotes más pequeños; entrenamiento/inferencia más lentos |
| Soporte de Paralelismo | Habilita el paralelismo de modelo/datos entre GPUs | Necesario para modelos muy grandes (ej. GPT-4) | Limita la escalabilidad en múltiples GPUs |
| Ancho de Banda de Memoria | Proporciona acceso a datos de alta velocidad | Acelera operaciones de tensor como multiplicaciones de matrices | Cuellos de botella en tareas intensivas de cómputo |
- Calcula tus Necesidades: Puedes estimar los requisitos de memoria basándote en el tamaño de tu modelo y el tamaño del lote.
- Ancho de Banda de Memoria: Un mayor ancho de banda permite una transferencia de datos más rápida entre la memoria de la GPU y los núcleos de procesamiento.
2. Potencia de Cómputo
- Núcleos CUDA: Más núcleos generalmente significan un procesamiento paralelo más rápido.
- Núcleos Tensor: Especializados en operaciones de matrices, cruciales para tareas de aprendizaje profundo.
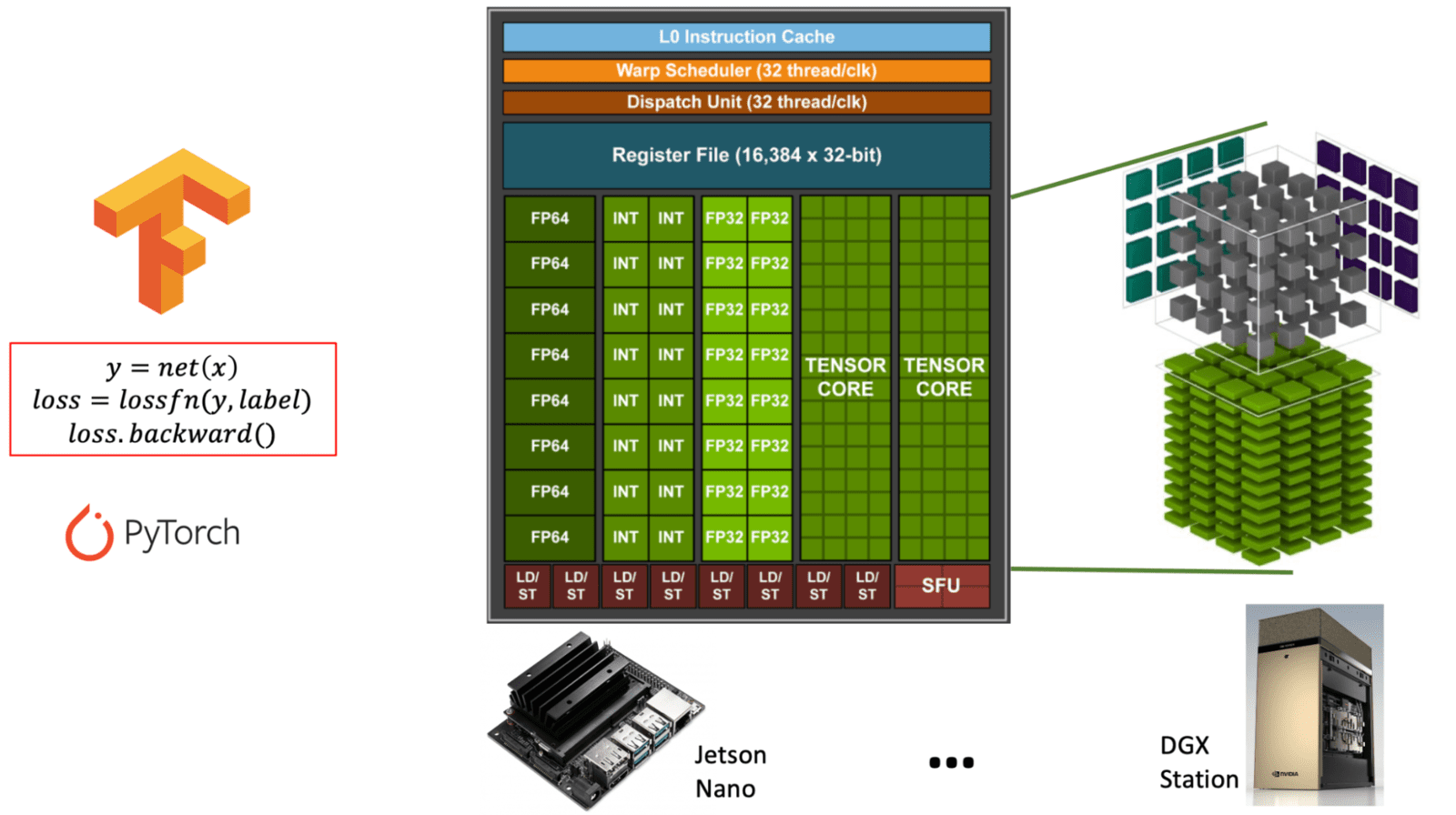
Diagrama que ilustra la diferencia entre los núcleos CUDA de propósito general y los núcleos Tensor especializados dentro de una arquitectura de GPU NVIDIA. (learnopencv.com) - Soporte FP16/INT8: El entrenamiento de precisión mixta puede acelerar significativamente los cómputos al tiempo que reduce el uso de memoria.
** Tabla: Comparación de Núcleos CUDA vs. Núcleos Tensor en GPUs NVIDIA. Esta tabla explica el propósito, función y uso de los núcleos CUDA frente a los Núcleos Tensor, ambos esenciales para diferentes tipos de cargas de trabajo de GPU, especialmente en IA y aprendizaje profundo. **
| Característica | Núcleos CUDA | Núcleos Tensor |
|---|---|---|
| Propósito | Cómputo de propósito general | Especializados para operaciones de matrices (matemáticas de tensor) |
| Uso Principal | Gráficos, física y tareas paralelas estándar | Tareas de aprendizaje profundo (entrenamiento/inferencia) |
| Operaciones | FP32, FP64, INT, aritmética general | Multiplicación y acumulación de matrices (ej. FP16, BF16, INT8) |
| Soporte de Precisión | FP32 (simple), FP64 (doble), INT | FP16, BF16, INT8, TensorFloat-32 (TF32), FP8 |
| Rendimiento | Rendimiento moderado para tareas de propósito general | Rendimiento extremadamente alto para tareas intensivas de matrices |
| Interfaz de Software | Modelo de programación CUDA | Se accede a través de librerías como cuDNN, TensorRT, o frameworks (ej. PyTorch, TensorFlow) |
| Disponibilidad | Presentes en todas las GPUs NVIDIA | Presentes solo en arquitecturas más nuevas (Volta y posteriores) |
| Optimización de IA | Limitada | Altamente optimizados para cargas de trabajo de IA (hasta 10x+ más rápidos) |
3. Comunicación entre GPUs
- NVLink: Si utilizas configuraciones multi-GPU, NVLink proporciona una comunicación GPU a GPU significativamente más rápida que PCIe.
NVLink es una tecnología de interconexión de alta velocidad desarrollada por NVIDIA para permitir una comunicación rápida entre GPUs (y a veces entre GPUs y CPUs). Aborda las limitaciones de PCIe tradicional (Peripheral Component Interconnect Express) ofreciendo un ancho de banda y una latencia significativamente mayores.
** Tabla: Resumen del Puente NVLink y Su Propósito. Esta tabla describe la función, beneficios y especificaciones clave de NVLink en el contexto de la computación basada en GPU, especialmente para cargas de trabajo de IA y alto rendimiento. **
| Característica | NVLink |
|---|---|
| Desarrollador | NVIDIA |
| Propósito | Permite la comunicación rápida y directa entre múltiples GPUs |
| Ancho de Banda | Hasta 600 GB/s total en versiones recientes (ej. NVLink 4.0) |
| Comparado con PCIe | Mucho más rápido (PCIe 4.0: ~64 GB/s total) |
| Latencia | Menor que PCIe; mejora la eficiencia multi-GPU |
| Casos de Uso | Aprendizaje profundo (LLMs), computación científica, renderizado |
| Cómo Funciona | Utiliza un puente NVLink (conector de hardware) para enlazar GPUs |
| GPUs Soportadas | GPUs NVIDIA de gama alta (ej. A100, H100, RTX 3090 con límites) |
| Software | Funciona con aplicaciones y frameworks compatibles con CUDA |
| Escalabilidad | Permite que múltiples GPUs se comporten más como una sola GPU grande |
Por Qué NVLink Importa para LLMs e IA
- Paralelismo de Modelo: Los modelos grandes (ej. LLMs tipo GPT) son demasiado grandes para una sola GPU. NVLink permite que las GPUs compartan memoria y carga de trabajo de manera eficiente.
- Entrenamiento e Inferencia Más Rápidos: Reduce los cuellos de botella de comunicación, impulsando el rendimiento en sistemas multi-GPU.
- Acceso Unificado a Memoria: Hace que la transferencia de datos entre GPUs sea casi perfecta comparada con PCIe, mejorando la sincronización y el rendimiento.
- Entrenamiento Multi-Tarjeta: Para el entrenamiento distribuido a través de múltiples GPUs, el ancho de banda de comunicación se vuelve crucial.
Tabla Resumen: Importancia de la Comunicación entre GPUs en el Entrenamiento Distribuido
( Tabla: Rol de la Comunicación entre GPUs en el Entrenamiento Distribuido. Esta tabla describe dónde se requiere una comunicación rápida de GPU a GPU y por qué es crítica para un entrenamiento escalable y eficiente de modelos de aprendizaje profundo. )
| Tarea de Entrenamiento Distribuido | Por Qué Importa la Comunicación entre GPUs |
|---|---|
| Sincronización de gradientes | Asegura la consistencia y convergencia en configuraciones de paralelismo de datos |
| Fragmentación de modelo | Permite un flujo de datos sin interrupciones en arquitecturas de paralelismo de modelo |
| Actualizaciones de parámetros | Mantiene los pesos del modelo sincronizados entre GPUs |
| Escalabilidad | Permite el uso eficiente de GPUs o nodos adicionales |
| Rendimiento | Reduce el tiempo de entrenamiento y maximiza la utilización del hardware |
4. Consumo de Energía y Refrigeración
- TDP (Potencia de Diseño Térmico): Las GPUs de mayor rendimiento requieren más energía y generan más calor.
- Soluciones de Refrigeración: Asegúrate de que tu sistema de refrigeración pueda manejar la disipación de calor de múltiples GPUs de alto rendimiento.
Opciones de GPU Populares Comparadas
** Tabla: Comparación de Características de GPUs NVIDIA para Aprendizaje Profundo. Esta tabla compara las especificaciones clave y capacidades de RTX 4090, RTX A6000 y RTX 6000 Ada, destacando sus puntos fuertes para cargas de trabajo de aprendizaje profundo. **
| Característica | RTX 4090 | RTX A6000 | RTX 6000 Ada |
|---|---|---|---|
| Arquitectura | Ada Lovelace | Ampere | Ada Lovelace |
| Año de Lanzamiento | 2022 | 2020 | 2022 |
| Memoria GPU (VRAM) | 24 GB GDDR6X | 48 GB GDDR6 ECC | 48 GB GDDR6 ECC |
| Rendimiento FP32 | ~83 TFLOPS | ~38.7 TFLOPS | ~91.1 TFLOPS |
| Rendimiento Tensor | ~330 TFLOPS (FP16, dispersión activada) | ~312 TFLOPS (FP16, dispersión) | ~1457 TFLOPS (FP8, dispersión) |
| Soporte Núcleo Tensor | 4ª Gen (con FP8) | 3ª Gen | 4ª Gen (con soporte FP8) |
| Soporte NVLink | ❌ (Sin NVLink) | ✅ (NVLink 2-way) | ✅ (NVLink 2-way) |
| Consumo de Energía (TDP) | 450W | 300W | 300W |
| Factor de Forma | Consumidor (2 ranuras) | Estación de Trabajo (2 ranuras) | Estación de Trabajo (2 ranuras) |
| Soporte Memoria ECC | ❌ | ✅ | ✅ |
| Mercado Objetivo | Entusiasta / Prosumidor | Profesional / Ciencia de Datos | Empresarial / Estación de Trabajo IA |
| PVPR (aprox.) | $1,599 USD | $4,650 USD | ~$6,800 USD (varía por vendedor) |
RTX 4090
- Arquitectura: Ada Lovelace
- Núcleos CUDA: 16,384
- Memoria: 24GB GDDR6X
- Ventajas: Mayor relación rendimiento-precio, excelente para cargas de trabajo de GPU única.
- Limitaciones: Sin soporte NVLink, menos memoria que las opciones profesionales.
- Mejor para: Entrenamiento de GPU única para modelos de tamaño mediano, investigadores con restricciones presupuestarias.
RTX A6000
- Arquitectura: Ampere
- Núcleos CUDA: 10,752
- Memoria: 48GB GDDR6
- Ventajas: Gran capacidad de memoria, soporte NVLink, estabilidad de nivel profesional.
- Limitaciones: Menor rendimiento bruto que las tarjetas más nuevas.
- Mejor para: Cargas de trabajo intensivas en memoria, configuraciones multi-GPU que requieren NVLink.
RTX 6000 Ada
- Arquitectura: Ada Lovelace
- Núcleos CUDA: 18,176
- Memoria: 48GB GDDR6
- Ventajas: Combina la arquitectura más reciente con gran memoria y NVLink.
- Limitaciones: Precio más alto.
- Mejor para: Configuraciones sin compromisos donde el presupuesto no es la principal preocupación.
Opciones de Hardware Especializado
GPUs con Factor de Forma SXM
** Tabla: Comparación de Factores de Forma SXM vs PCIe para GPUs. Esta tabla describe las principales diferencias y ventajas de SXM sobre PCIe estándar para aprendizaje profundo, HPC y aplicaciones de centro de datos. **
| Característica | Factor de Forma SXM | Factor de Forma PCIe |
|---|---|---|
| Tipo de Conexión | Interfaz de zócalo directo (no a través de ranura PCIe) | Se enchufa en ranuras PCIe |
| Entrega de Energía | Hasta 700W+ por GPU | Típicamente limitado a 300–450W |
| Diseño Térmico | Refrigeración optimizada mediante disipadores personalizados, opciones de refrigeración líquida | Refrigerado por aire con ventiladores estándar |
| Ancho de Banda/Latencia | Soporta NVLink con mayor ancho de banda y menor latencia | Limitado a la velocidad del bus PCIe |
| Interconexión GPU | Malla NVLink de alto ancho de banda entre múltiples GPUs | Comunicación peer-to-peer de menor ancho de banda sobre PCIe |
| Tamaño e Integración | Diseñado para entornos de servidor densos (ej. NVIDIA HGX) | Cabe en estaciones de trabajo o racks de servidor estándar |
| Escalabilidad de Rendimiento | Excelente para configuraciones multi-GPU | Limitada por el bus PCIe y restricciones de energía |
| Caso de Uso Objetivo | Centros de datos, entrenamiento de IA, HPC, plataformas en la nube | Escritorio, estación de trabajo, cargas de trabajo empresariales ligeras |
- Opciones: V100, A100, H100 (con conectores SXM2/SXM4/SXM5)
- Ventajas: Límites de energía y ancho de banda más altos que las versiones PCIe.
- Usado en: Plataformas de servidor de gama alta como los sistemas NVIDIA DGX.
Soluciones Multi-Nodo
- Plataformas de servidor que soportan 4-8 GPUs por nodo.
- Ejemplos: Dell C4140, Inspur 5288M5, GIGABYTE T181-G20.
Marco de Decisión
- Identifica primero tus requisitos de memoria.
- Si tus modelos no caben en memoria, el rendimiento se vuelve irrelevante. ** Tabla: Entendiendo el Error "Sin Memoria" (OOM) en Aprendizaje Profundo. Esta tabla explica qué causa los errores OOM, por qué ocurren, y cómo los límites de memoria de la GPU afectan el entrenamiento y la inferencia de modelos. **
| Aspecto | Explicación |
|---|---|
| ¿Qué es OOM? | Error "Out Of Memory" (Sin Memoria) — ocurre cuando un modelo o un lote no cabe en la VRAM de la GPU. |
| Causa Raíz | Los pesos del modelo, las activaciones y los datos exceden la memoria de la GPU disponible. |
| Cuándo Sucede | Durante la inicialización del modelo, el paso hacia adelante, la retropropagación, o al cargar lotes grandes. |
| Componentes Afectados | Parámetros del modelo, estados del optimizador, mapas de activación, gradientes. |
| Memoria GPU (VRAM) | Recurso finito que determina cuán grande o complejo puede ser un modelo. |
| Primera Verificación | Siempre compara el tamaño del modelo + requisitos del lote con la VRAM disponible. |
| Desencadenantes Típicos | - Modelo demasiado grande - Tamaño del lote demasiado alto - Precisión mixta no utilizada - Fuga de memoria (memory leak) |
| Estrategias de Mitigación | - Reducir el tamaño del modelo - Disminuir el tamaño del lote - Usar gradient checkpointing - Aplicar precisión mixta (FP16/8) - Usar GPUs más grandes o múltiples |
-
Determina tus necesidades de comunicación.
- ¿Entrenamiento multi-GPU? ¿Necesitas NVLink? ¿O PCIe es suficiente?
-
Ajústate a tu presupuesto.
- Para máxima relación precio/rendimiento: RTX 4090.
- Para cargas de trabajo sensibles a la memoria con presupuesto moderado: A6000.
- Para rendimiento de vanguardia con gran memoria: RTX 6000 Ada.
-
Considera la trayectoria de investigación a largo plazo.
- Para necesidades de investigación en evolución con modelos potencialmente más grandes: Elige opciones con mayor memoria.
Consejos Prácticos de Despliegue
- Al comprar para investigación académica, asegúrate de que los proveedores puedan emitir facturas adecuadas para el reembolso.
- Considera configuraciones heterogéneas si se anticipan diferentes cargas de trabajo.
- Para sistemas multi-tarjeta, especifica las tarjetas con
CUDA_VISIBLE_DEVICESal ejecutar experimentos. ** Tabla: Rol deCUDA_VISIBLE_DEVICESen la Gestión Multi-GPU. Esta tabla muestra cómo funciona la variable, por qué es útil, y escenarios donde mejora la asignación y eficiencia de la GPU. **
| Aspecto | Descripción |
|---|---|
| Función | Controla qué GPUs son visibles para un proceso |
| Ejemplo de Sintaxis | CUDA_VISIBLE_DEVICES=0,1 python train.py — Solo usa las GPUs 0 y 1 |
| Reasignación de Dispositivos | Internamente reasigna los dispositivos listados a IDs lógicos (ej. 0 se convierte en cuda:0) |
| Aislamiento | Evita solapamientos entre trabajos concurrentes o usuarios en servidores de GPU compartidos |
| Optimización de Rendimiento | Permite la asignación precisa de GPUs para balanceo de carga |
| Entrenamiento Distribuido | Esencial para asignar las GPUs correctas por nodo o trabajador |
| Depuración/Pruebas | Útil para probar código en una GPU específica o evitar las defectuosas |
| Uso Dinámico de la GPU | Permite que los scripts se ejecuten en diferentes conjuntos de GPUs sin modificar el código |
- Prueba tus cargas de trabajo a fondo para determinar los requisitos reales de memoria antes de comprar.
Evaluando cuidadosamente estos factores frente a tus necesidades de investigación específicas y restricciones presupuestarias, puedes seleccionar la solución de GPU más apropiada para tu entorno de desarrollo de aprendizaje profundo y LLM.